
On-chain data has significantly changed in the last few years, primarily driven by the arrival of DeFi. There has been an increase in the number of tangible assets deposited on the blockchain with the maturity of products such as AMM. The transactions being done on the blockchain have become more complex as users can now stake, swap, lend and farm out their crypto, compared to the simple transfers of past years. The increasing complexity of blockchain transactions has led to higher gas fees on most blockchain networks increasing counterfeiting costs while raising the value of each transaction.
Soda ID was created based on the above factor. Its main aim is to accumulate large swathes of on-chain data and perform multiple operations such as extraction, cleansing, training, classification and archiving to eventually generate a user portrait based on the activities recorded via the user’s blockchain wallet. Soda ID continuously collects user data based on the individual’s on-chain actions. The protocol intends to build a reliable credit score for its users based on the data collected and each user’s off-chain social information. Soda ID intends to become a crucial part of the credit lending process and a vital component of the web3 world.
How Soda ID Works
Soda ID works via multiple data pipelines that collect and analyze the data generated by each user.
Data Flow
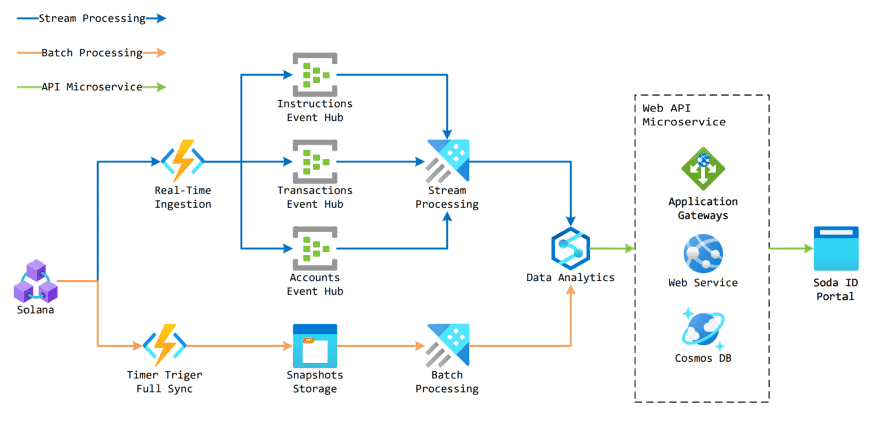
The image above shows how the protocol collects almost real-time data on users by monitoring the changes in their online accounts and the transactions they make. This process is known as stream processing and is represented by the blue pipeline.
The orange pipeline represents batch processing. It entails synchronising the data collected by fetching the complete data at timed intervals and storing the data in the data warehouse. Batch processing ensures the integrity and consistency of the data collected.
Data Processing
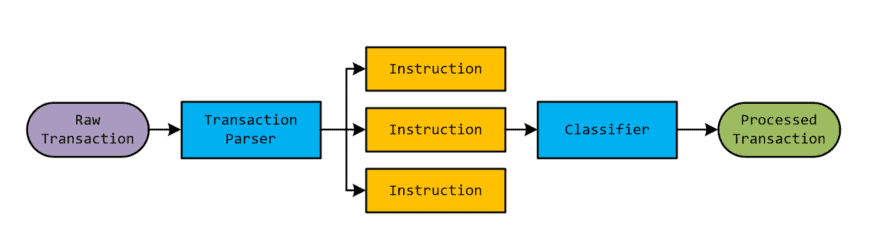
Once the data has been collected and its accuracy confirmed in the first step, it is archived via the data analytics service. Next, it is processed to generate specific information classified as an instruction. The features of the classified information are then extracted.
Data Training
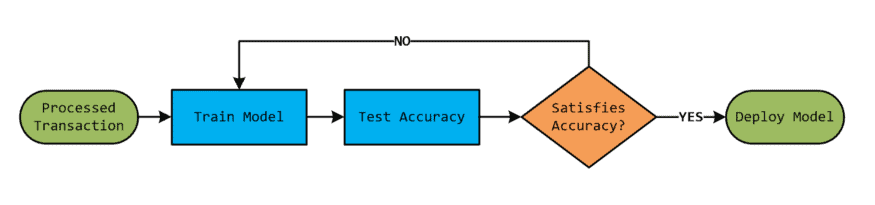
Next, the data is trained and backtested using machine learning algorithms by performing data labelling to create data sets, then divided into different datasets for model training.
Data visualization
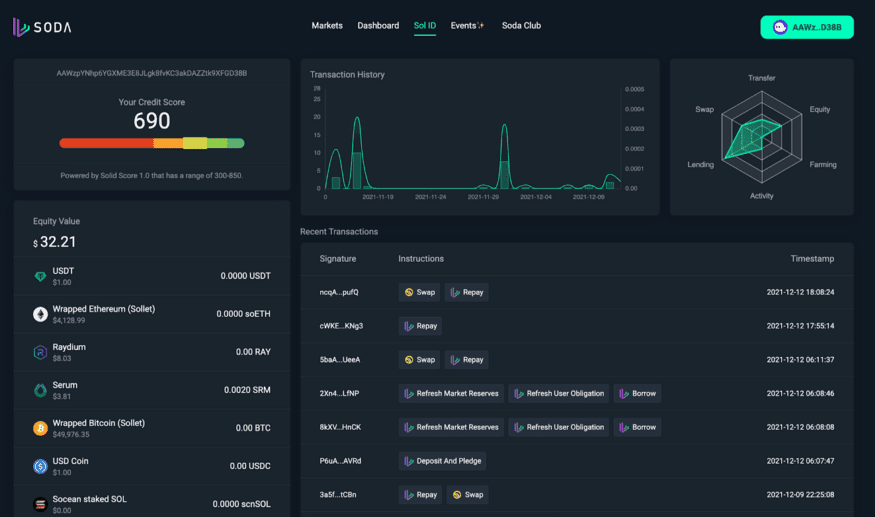
This is the second last step that allows the data to be displayed on a dashboard with the user’s profile as reflected in their wallet activities.
Scenarios
This is the last step in the process, and it allows for refined operations such as reasonable airdrop allocations, the distribution of IDO whitelists, among other functions.
For more details check out Soda ID: Financial Identity for Web3.0.